2025
WSI-Agents: A Collaborative Multi-Agent System for Multi-Modal Whole Slide Image Analysis
Xinheng Lyu, Yuci Liang, Wenting Chen, Meidan Ding, Jiaqi Yang, Guolin Huang, Daokun Zhang, Xiangjian He, Linlin Shen
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2025 Oral
We propose WSI-Agents, a novel collaborative multi-agent system for multi-modal WSI analysis that integrates specialized functional agents with robust task allocation and verification mechanisms. The system enhances both task-specific accuracy and multi-task versatility through three key components: task allocation, verification mechanisms, and summary modules.
WSI-Agents: A Collaborative Multi-Agent System for Multi-Modal Whole Slide Image Analysis
Xinheng Lyu, Yuci Liang, Wenting Chen, Meidan Ding, Jiaqi Yang, Guolin Huang, Daokun Zhang, Xiangjian He, Linlin Shen
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2025 Oral
We propose WSI-Agents, a novel collaborative multi-agent system for multi-modal WSI analysis that integrates specialized functional agents with robust task allocation and verification mechanisms. The system enhances both task-specific accuracy and multi-task versatility through three key components: task allocation, verification mechanisms, and summary modules.
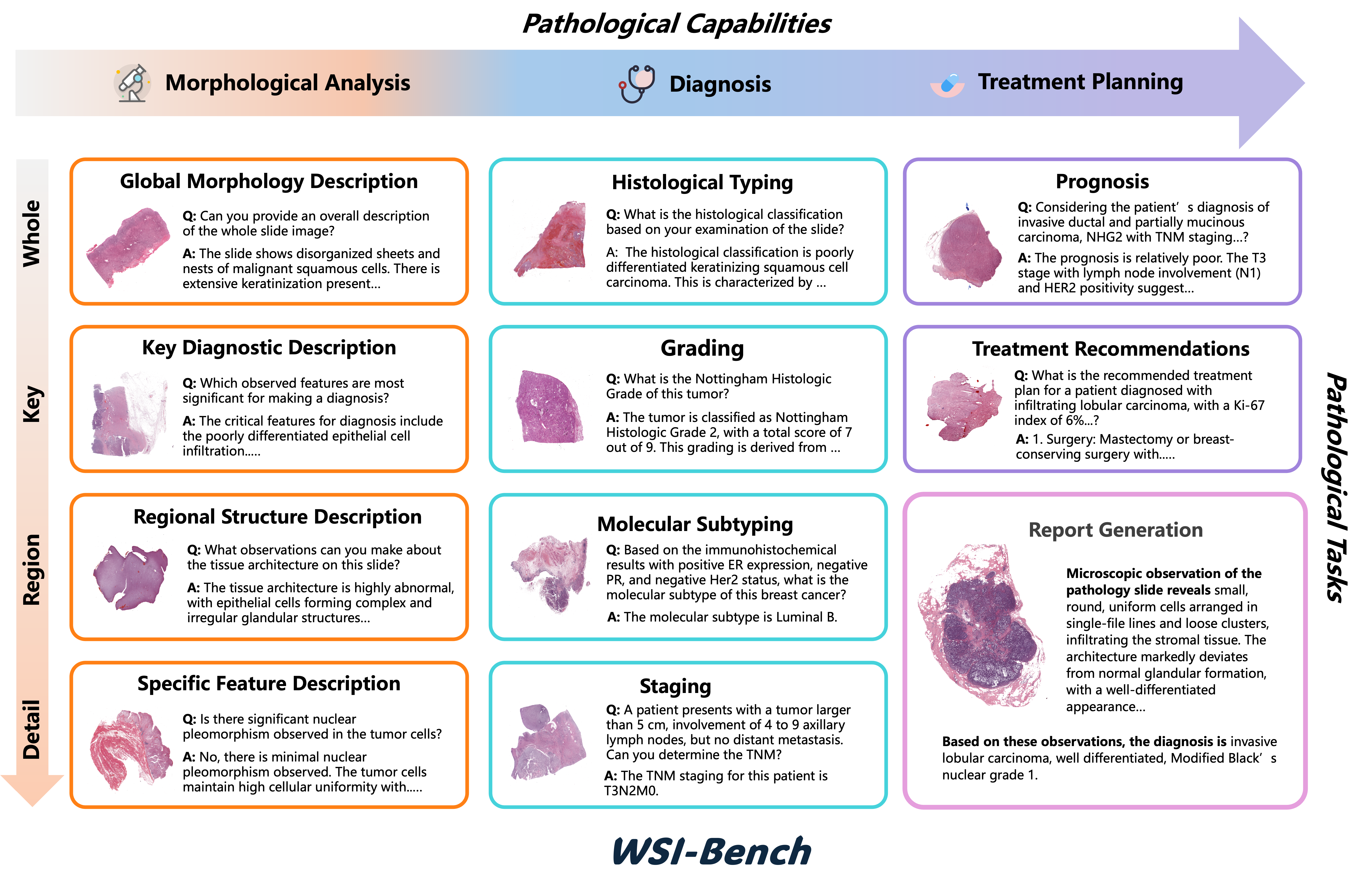
WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image
Yuci Liang*, Xinheng Lyu*, Wenting Chen, Meidan Ding, Jipeng Zhang, Xiangjian He, Song Wu, Xiaohan Xing, Sen Yang, Xiyue Wang, Linlin Shen (* equal contribution)
International Conference on Computer Vision (ICCV) 2025
We introduce WSI-LLaVA, an MLLM framework for gigapixel WSI understanding with a three-stage training strategy that provides detailed morphological findings to explain diagnostic reasoning. We also present WSI-Bench, the first large-scale morphology-aware benchmark containing 180k VQA pairs from 9,850 WSIs across 30 cancer types.
WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image
Yuci Liang*, Xinheng Lyu*, Wenting Chen, Meidan Ding, Jipeng Zhang, Xiangjian He, Song Wu, Xiaohan Xing, Sen Yang, Xiyue Wang, Linlin Shen (* equal contribution)
International Conference on Computer Vision (ICCV) 2025
We introduce WSI-LLaVA, an MLLM framework for gigapixel WSI understanding with a three-stage training strategy that provides detailed morphological findings to explain diagnostic reasoning. We also present WSI-Bench, the first large-scale morphology-aware benchmark containing 180k VQA pairs from 9,850 WSIs across 30 cancer types.